
A more recent post on this topic is available on Julian’s Substack.

Rubrics reduce subjectivity in evaluation
A word that often gets misused in evaluation is ‘subjective’. Evaluative judgements are not subjective if they are supported by credible evidence, explicit values and logical argument. Evaluative rubrics provide a vital logical link between empirical evidence and evaluative judgements.
Rubrics are inter-subjective – an agreed social construct used by a group of people for an agreed purpose. Just like other inter-subjective constructs, such as bank accounts, employment contracts and systems of democracy, evaluative rubrics are real, verifiable, and serve an important purpose. Rubrics make evaluative reasoning explicit.
Evaluation has been defined as “the systematic determination of the merit, worth or significance of something” (Scriven, 1991). In plainer language, the core purpose of evaluation is to determine “how good something is, and whether it is good enough” (Davidson, 2005). Therefore, evaluation involves making judgements: “it does not aim simply to describe some state of affairs but to offer a considered and reasoned judgement about that state of affairs” (Schwandt, 2015).
The fundamental problem in this endeavour is “how one can get from scientifically supported premises to evaluative conclusions” (Scriven, 1995) – in other words, how to make a sound judgement using a logical and traceable process.
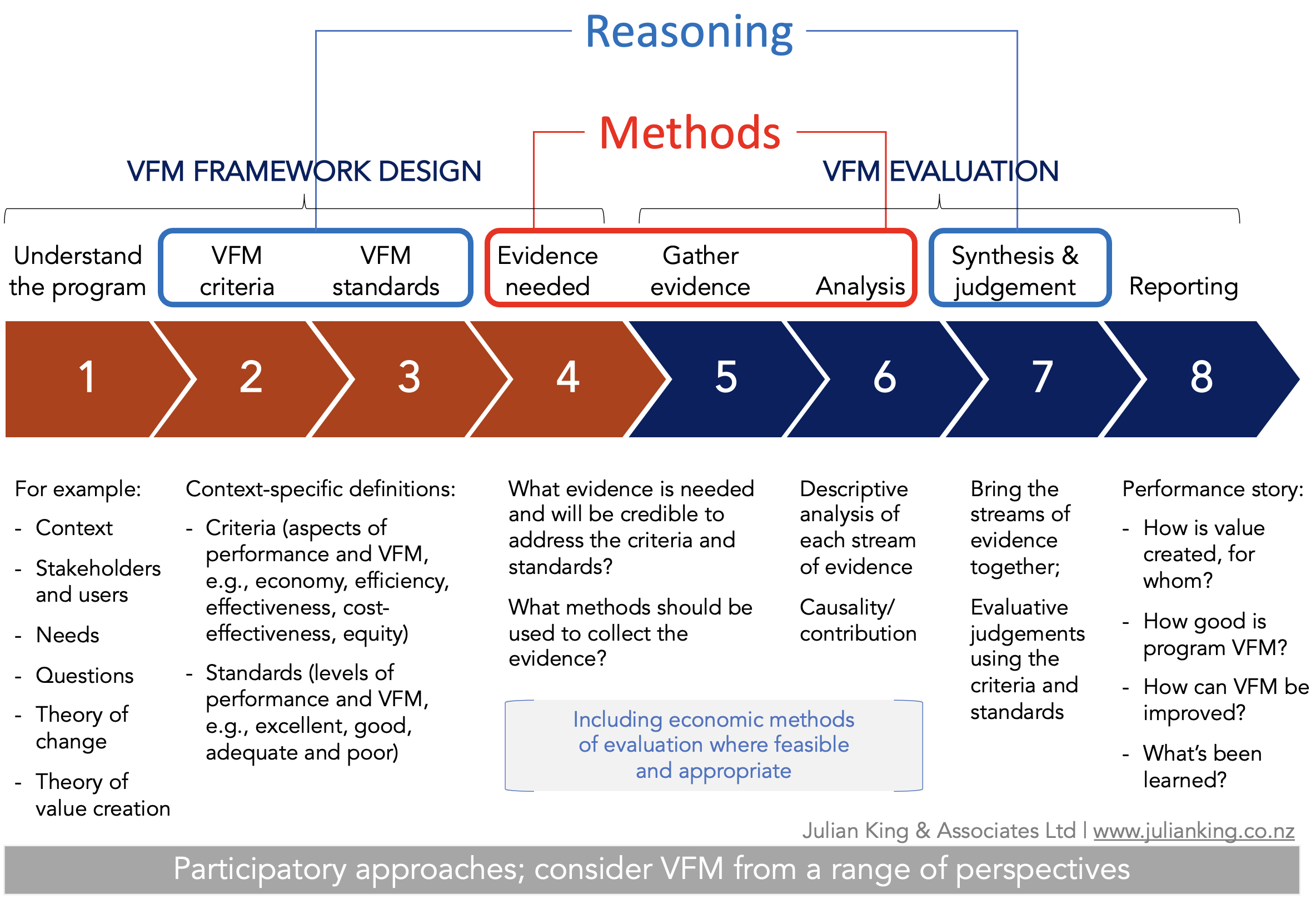
Explicit evaluative reasoning provides the means to make robust judgements from evidence. Essentially, it involves developing definitions of what ‘good’ quality, value, performance, etc, would look like. These definitions are developed before the evidence is gathered and analysed, providing an agreed basis for making judgements.
Although there is more than one way to approach this task, a widely used approach is to:
- Establish criteria of merit, worth or significance – the dimensions of performance that are relevant and important to an evaluative judgement
- Define performance standards for each criterion, in order to distinguish between ‘excellent’, ‘good’, ‘acceptable’ or ‘poor’ performance
- Gather and analyse evidence of performance against the standards
- Synthesise the results into an overall judgement (Fournier, 1995).
The use of criteria and standards supports evaluative reasoning, which is core to good evaluation (Yarbrough, Shulha, Hopson, and Caruthers, 2011). Evaluative reasoning enhances the credibility and use of evaluation for accountability, learning and adaptation, by providing a transparent (and therefore challengeable) basis for making judgements (King et al., 2013).
Rubrics
Criteria and standards can be presented in tables called rubrics (Davidson, 2005). My colleagues and I wrote about how the use of rubrics has enhanced our evaluation practice, in this open source journal. Judy Oakden provided a practice-based example on the Better Evaluation website.
Here’s one example of what a rubric can look like. This particular rubric is generic – it can be applied to any criteria.

Evaluative rubrics provide a sound and transparent basis for:
- Defining what good quality and value look like
- Identifying what evidence is needed to support an evaluation
- Organising the evidence so that it is easier and more efficient to analyse
- Interpreting the evidence on an agreed basis
- Reaching clear judgements, supported by evidence and reasoning
- Telling a compelling and accurate performance story.
The process of making judgements can feel a little unfamiliar to anybody trained in an academic research discipline, because it involves using evidence in a new way: comparing the evidence to the criteria and standards and being deliberative about what level of performance it points to. An evaluative judgement cannot be made by an algorithm: it involves weighing multiple pieces of evidence – some of which may be ambiguous or contradictory – guided by the criteria and standards, to make transparent and defensible judgements with clear rationale.
Subjectivity
The use of criteria and standards to make judgements about performance from the evidence may be criticised by some stakeholders as being ‘too subjective’ or ‘less robust’ than a purely measurement-based system. This criticism confuses methods (how we gather knowledge) with reasoning (how we make judgements).
On the first issue, methods: it does not automatically follow that quantitative methods are more ‘objective’ or robust than qualitative methods. That’s an antiquated debate and we need to leave it behind. Both forms of evidence are valid for specific purposes (Donaldson, Christie & Mark, 2015), and if we privilege one over the other, we might miss something important. Both quantitative and qualitative methods are vulnerable to bias at every step of the research process from design to data collection, analysis, interpretation of results, and how they’re reported. We can’t rank methods from most objective to least objective. We have to carefully choose the right methods for the context, and be transparent about their limitations.
Moving on to the second issue, reasoning: No matter what evidence is collected, whether numbers or stories, somebody has to make judgements from the evidence. Either quant or qual data (or preferably, both together) can support a valid, traceable and challengeable judgement – or, if poorly used and reported, an opaque and invalid one. Rubrics are a way of making the reasoning explicit.
As an inter-subjective construct, a rubric isn’t a universal truth – it’s a matter of context (where, when) and perspective (to whom). While rubrics reduce personal subjectivity, they remain vulnerable to shared bias when developing criteria and standards, and when using them to make judgements (Scriven, 1991). Therefore it’s important to guard against cultural biases and groupthink by involving an appropriate mix of stakeholders (King et al., 2013).
Dr. E. Jane Davidson, author of the book Evaluation Methodology Basics (2005) and a pioneer in the use of rubrics to support evaluative reasoning, notes that “evaluation is an intensely political activity” and as such, can attract criticisms such as:
- “Well, that’s just your opinion about the programme”
- “Yes, but who defines ‘adequate’ performance?”
- “Who are you to impose your values on our programme?”
- “These conclusions are just so subjective!”
These comments and questions assume that evaluative conclusions are based on personal values. Michael Scriven said there are actually four meanings for the word ‘subjective’. Jane explains these four meanings as follows:
- “Arbitrary, idiosyncratic, unreliable, and/or highly personal (i.e., based on personal preferences and/or cultural biases) – this is usually what people insinuate when they say something is ‘all just subjective’. The values used in an evaluation should not be the personal values, preferences and biases of the evaluator, but an agreed set of filters for interpreting the evidence” (e.g., a rubric)
- “Assessment or interpretation by a person, rather than a machine or measurement device, of something external to that person (e.g., expert judgement of others’ skills or performance) – in evaluation, evaluative reasoning and making judgements are mandatory, and it is appropriate to use expert judgement” (just as we expect a doctor to make judgements about our health based on all the information they can gather)
- “About a person’s inner life or experiences (e.g., headaches, fears, beliefs, emotions, stress levels, aspirations), all absolutely real but not usually independently verifiable” – in fact, these experiences can be systematically gathered and analysed (quantitatively or qualitatively) and, in some research and evaluation, are an important source of evidence
- “A derogatory term for any kind of qualitative or mixed method evidence. As evaluators, we know this criticism is not true and we should not let anyone away with this!”
Jane adds: “Of course, we all have our ‘lenses’ and ways of looking at the world, things that we are prone to notice, not notice, emphasise, etc., but the real issue is ensuring that our lenses/preferences do not interfere with the evaluation to the extent that we:
- Exclude, ignore or underweight important information or perspectives
- Inappropriately include or give undue weight to something, or
- Draw a conclusion that is not justified.”
Rubrics reduce subjectivity. They set out a shared set of values and make evaluation more transparent. Ask not whether an evaluation is ‘objective’ but whether the reasoning is explicit.
References
Davidson, E.J. (2017). Personal communication.
Davidson, E.J. (2005). Evaluation Methodology Basics: The nuts and bolts of sound evaluation. Thousand Oaks, CA: Sage.
Donaldson, S., Christie, C.A., Mark, M. (2015). Credible and Actionable Evidence: The foundation for rigorous and influential evaluations. 2nd Edition. Sage.
Fournier, D. M. (1995). Establishing evaluative conclusions: A distinction between general and working logic. In D. M. Fournier (Ed.), Reasoning in Evaluation: Inferential Links and Leaps. New Directions for Evaluation, (58), 15-32.
King, J., McKegg, K., Oakden, J., Wehipeihana, N. (2013). Rubrics: A method for surfacing values and improving the credibility of evaluation. Journal of MultiDisciplinary Evaluation, Vol 9 No 21.
Schwandt, T. (2015). Evaluation Foundations Revisited: Cultivating a Life of the Mind for Practice. Redwood City: Stanford University Press.
Scriven, M. (1991). Evaluation Thesaurus. Newbury Park, CA: Sage.
Yarbrough, D. B., Shulha, L. M., Hopson, R. K., and Caruthers, F. A. (2011). The program evaluation standards: A guide for evaluators and evaluation users (3rd ed.). Thousand Oaks, CA: Sage
March, 2019
